

Guide to Data Duplication and Data Cleansing
Today, businesses are dealing with more data than ever. By 2025, global data creation is expected to expand to more than 180 zettabytes — that’s more than quadruple the amount of data that existed in 2020. With more data comes more data management challenges. These large data sets are prone to redundant or duplicate copies that minimize an organization’s storage space and reduce data integrity.
One of the main ways to eliminate data management challenges is by cleansing and deduplicating data stores. Below, we provide a clear definition of data duplication and its challenges, and discuss in detail what data deduplication is and its benefits.
Table of Contents
- The Challenges and Consequences of Data Duplication
- What Is Data Cleansing and Deduplication?
- Types of Data Deduplication
- Benefits of Data Deduplication
The Challenges and Consequences of Data Duplication
Data duplication occurs when the same data entries exist in the same storage system or across multiple systems. It’s often a result of human error, lack of standard data formats and data integration issues. Duplicate data results in various consequences within an organization, including but not limited to the following:
1. Inhibits Data-driven Decision-making
Duplicate data affects the quality and accuracy of reports you generate because the same metric may be counted more than once. As a result, management is unable to make informed decisions.
2. Wastes Time and Resources
Sifting through duplicate records is time-consuming and diminishes employees’ productive hours. It also wastes company resources because you may incur higher storage costs — keeping multiple copies of the same data uses up valuable space that could be downsized or used to store other unique data.
3. Leads to Poor Customer Service
Duplicate records may contain errors, which negatively impact how customers and prospects perceive your brand. These mistakes also result in a lack of personalization, which makes customers lose trust in your brand.
4. Increases Marketing Costs
When looking at duplicate records, sales and marketing teams waste time and resources following the wrong leads with minimal conversion chances. Duplication increases marketing spend because of activities such as sending the same piece of content to the same recipient multiple times.
What Is Data Cleansing and Deduplication?
Data cleansing or cleaning is the process of identifying, correcting or removing inaccuracies, inconsistencies, flaws and errors from data sets, databases or tables. It ensures data accuracy and solves quality and reliability issues common with duplicate data. However, data cleansing is not enough to eliminate all data issues. The cleansed data still needs to be standardized to convert it into a consistent format, normalized by organizing it within a data set, and analyzed to provide valuable insights.
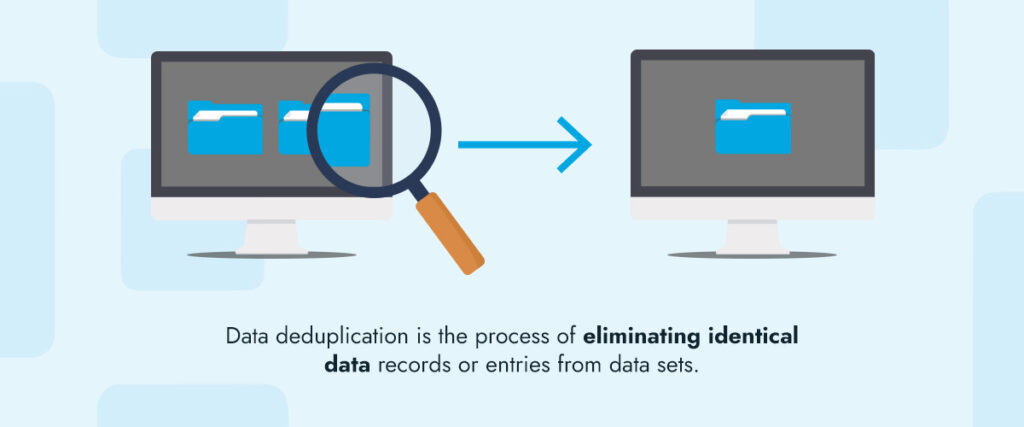
Quality checking also helps to ensure you make the right decisions, but the last step eliminates all instances of data duplication — deduplication. Data deduplication is the process of eliminating identical data records or entries from data sets. It involves dividing the data into several data blocks assigned with unique hash codes. If one hash code matches another, then it’s considered a duplicate and is deleted. The duplicates can be detected across several data types, servers, directories and locations.
Data deduplication helps small and medium-sized businesses (SMBs) manage their growing amounts of data. As a result, they can save on data storage space, reduce network load by ensuring less data is transferred and maximize their bandwidth.
Types of Data Deduplication
Data deduplication can be categorized according to where it occurs. Below are a few deduplication methods.
Source Deduplication
Source deduplication occurs at the point where new data is generated, typically inside the file system, which scans for redundancies in new files before data backup. Source deduplicating optimimizes storage utilization by saving storage space and reducing bandwidth consumption.
Target Deduplication
Target deduplication involves deleting or eliminating any duplicate data copies found in areas other than where the original data was generated. All the data near the storage destination is checked, which increases costs and may burden the network.
There is another categorization of data deduplication that depends on the timing of the processes:
Inline Deduplication
Inline deduplication involves real-time data analysis as it’s ingested into the system. Inline deduplication reduces network traffic and the bandwidth an organization needs by preventing the transfer and storage of duplicate data. That said, it may cause bottlenecks and reduce the primary storage performance.
Post-process Deduplication
Post-process deduplication removes redundant data after it’s been uploaded to a storage device. While it takes up a lot of storage space, it provides you with the flexibility to eliminate duplication in specific workloads and ensure quick recovery of the latest backups.
Benefits of Data Deduplication
Businesses that handle considerable amounts of data need to remain proactive about avoiding data duplication. Deduplication can be an effective strategy to remove duplicate data sets and help teams organize their data. Some of the top benefits of data deduplication include:
1. Save On Storage Costs
Removing outdated, redundant data frees up valuable storage space, enabling businesses to make the most of their storage equipment. You end up saving money by spending less on power, physical storage space and hardware updates.
2. Increased Data Accuracy and Quality
Eliminating similar or redundant copies of data improves data quality by ensuring only a unique, single data instance is stored. With higher data quality comes reliable insights and metrics.
3. Improved Storage Allocation
Data deduplication reduces the amount of data a business needs to store and manage. This decreases the wastage of storage space and ensures only useful data makes up an organization’s storage capacity.
4. Enhanced Recovery Speeds After a Data Breach
Removing redundant data decreases the stress on network bandwidth to facilitate quick disaster recovery. The fast and efficient recovery of backup data reduces downtime, and operational disruptions are minimized in case of cyberattacks, natural disasters or other disruptions.
5. Enhanced System Performance and Efficiency
Data deduplication improves system performance and efficiency by ensuring a faster backup process and data retrieval while reducing transfer times and bandwidth usage.
6. Meet Compliance Regulations
Reducing the amount of unstructured data being stored and managed helps in meeting compliance regulations.
Contact Contigo for Data Deduplication Services
Is your company struggling with data duplication issues or other data management challenges? Partnering with the right IT company can help you get your data organization back on track.
Contigo is a reliable IT management service provider that can help you with data deduplication, data compliance and storage optimization. We are headquartered in Austin, Texas, and provide our IT service provider and tech support services to companies based in Central Texas and beyond. Our clients include companies in numerous industries, from engineering and manufacturing to health care.
You can count on us for premier data deduplication services and customized backup solutions that ensure business continuity even in the event of a disaster. Our expertise and knowledge will make it easy and seamless for you to integrate this crucial process into your business. Contact us today to learn more about our data cleansing and deduplication services.
